一、为什么网站要做可控的SEO?
- SEO行业内是没法说清楚谁比谁的水平高的,一个公司的专职SEO人员提的优化需求通常优先级很低,因为没有人觉得优化后网站流量肯定会提升,这都是不可控带来的问题。
- 可控意味着可以度量、可以监测,更重要的是可以预测。
1.1 SEO可以做到可控吗?
- 可以
1.2 如何做到可控的SEO?
- 一切从常识出发
- 用数据说话(有了数据才有底气,才能确定)
- 重视相关技术(SQL会应用只需要半天)
1.3 做好SEO的两个思路
- 了解搜索引擎的算法规则,此路不太可行,了解所有细节规则的人是个位数,是搜索引擎公司的核心机密
- 做好确定的部分,然后逐渐迭代尝试不确定的部分,这就是现在说的MVP思维啊
二、从常识出发得出的SEO公式
2.1 SEO核心公式
用户通过搜索引擎达到网站之前,必经的流程里分析,可得出:
1
SEO流量 = 整体收录量 × 整体排名 × 整体点击率
- 这三个公式里的三个要素同等重要
- 所有影响SEO流量都不超过上面三个方面
- 网站整体点击率范围:0.5% ~ 5%
- 百度排名第1的网页点击率在29%左右
2.2 整体收录量核心公式
常识:网站在收录之前发生了什么事情?
- 搜索引擎爬虫爬取网站页面
- 网站有70万页面,但爬虫在一定时间内只爬了10万
- 爬到的页面通过质量标准进行判断,如果通过质量标准则被收录
- 爬虫后期也会动态判断页面质量,如果质量较低后期也会被删除收录
公式:
1 | 整体收录量 = 搜索引擎页面抓取量 × 页面质量 |

案例一
详见(【案例】利用SEO公式抽丝剥茧的分析网站流量下跌的原因)[https://blog.onlyfew.cn/2020/05/31/guoping-seo-eg-01/]
从本案例可以看出,我们已经做到了基本可控。
2.2.1 搜索引擎页面抓取量由什么决定?
常识:
- 爬虫停留时间越长爬取的页面越多;
- 爬虫爬取单个页面的时间越短,爬取效率越高;
经验:
- 网站有50万个页面,通过日志发现爬虫有30万的爬取记录,去重后实际爬取了10万的页面。
公式:
1 | 搜索引擎页面抓取量 = 爬虫总的停留时间 ÷ 单个页面停留时间 |

案例1:携程英文站 ctrip.com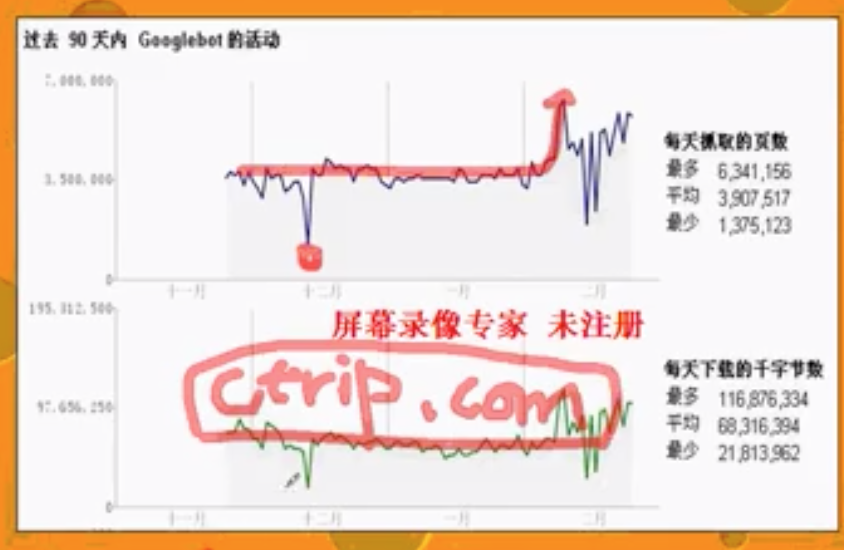
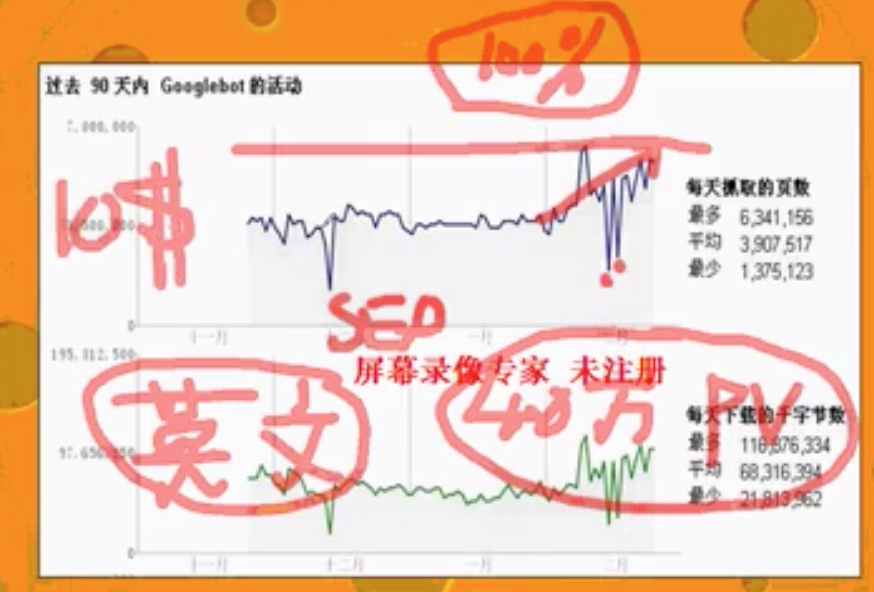
- 通过做nofollow的改动(花了2个小时),将抓取量提升了一倍(100%),实际收录量提升了20%~30%,导致流量涨了40万PV,之前携程愿意花10美金给一个UV。
- 中间下滑的部分是因为服务器宕机,承受不住。
案例2:alibaba.com优化页面访问速度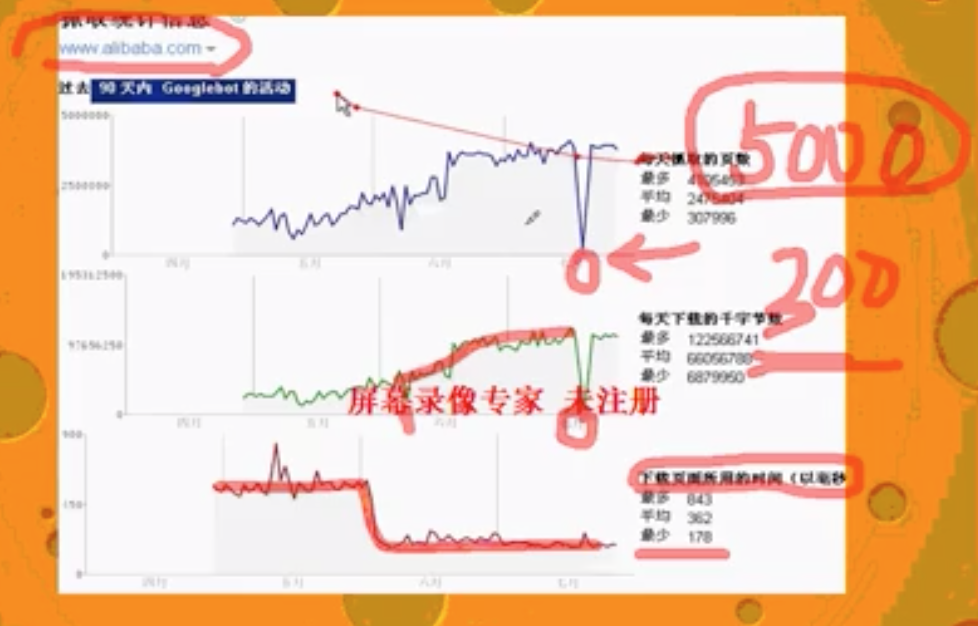
- 单个页面停留时间要越短越好;页面访问速度越快,停留时间越短;
- 单页面停留时间在300ms下就非常优秀了,但很多网站通常在5000ms;
- 爬虫的活跃时间是在晚上;所以要保障晚上系统的稳定性;不要被技术人员搞了乌龙;
2.2.1.1 如何提升页面访问速度?
常识:
- 搜索引擎通过爬虫抓取页面的全流程的时间总和即为页面访问时间。所以从这个全流程去分析影响因素即可。
- 影响因素有:爬虫所在网络与网站所在网络、DNS解析、CDN网络、机房出口带宽(一般是共享的)、服务器配置(CPU、内存、硬盘、主板等)、服务器操作系统(windows server2003、2008、linux)、服务器web server、软件系统(含页面)
经验:
- 百度的爬虫机房大部分在北京联通(讲课时,需要拿数据验证),如果你的网站只部署在电信机房,访问速度就会很慢,最好是双线部署(有两个IP),或者部署在“BGP”(边境网关协议,只有一个IP);
- DNS解析也是可以优化的,要选优质供应商;
- 使用CDN网络,可能没有爬虫日志,需要CDN供应商提供;
- 机房出口带宽(30G/5G)是否够用不要看绝对数,要看背后提供的服务,比如已经在提供视频服务,可能带宽已经很满了;
- 一般用windows server的网站的SEO都不可控;
- 软件系统有自研和用开源两种选择,通常自研的稳定性不太够,需要迭代;
- google的speed test,只是针对web的页面层级的;
2.2.1.2 爬虫总的停留时间
这部分对于初学者来说更多的是经验,不是常识了。
经验:
- 爬虫总的停留时间分为两部分:爬虫主动给的时间、爬虫被动给的时间;
- 爬虫主动给的时间有3小时、5小时、8小时、24小时;和网站的权重相关,权重越高爬虫来的次数越多停留时间越长;国平老师了解到的超过24小时的网站是个位数;
- 网站权重,是搜索引擎对网站的重视程度,也可以理解为信任程度;通过爬取时间可以反推权重;
- 如果新发布的内容很快就会被收录,通常说明权重较高;(百度搜索)
- 国平老师的光年论坛,8~9个爬虫,几乎24小时都在的,所以光年论坛的权重还是很高的;
- 爬虫的原理是随机漫游爬取的;
a. 不同的爬虫之间是有可能重复爬取一个页面的,同一个爬虫内的不同线程是会去重爬取的;
b. 爬虫在爬取一个页面前不会做页面判断的,因为判断页面需要进行相关分析,非常耗时的;
c. 统计学上来说,随机漫游,基本上所有的页面都会漫游到;
d. 爬虫在某个页面上随机漫游时,头部和尾部的模板部分会尽量排除掉再去随机;(没说太清楚?) - 爬虫被动时间:因为爬虫原理推导的,外部链接带来的时间。
- 如果你能做10万个外部链接,你有两个选择,一个是将10万个外部链接都链接到首页,另一个是将10万个外部链接链接到不同的页面,根据上面的分析,当然是后者好,可以有效的增加被动爬取时间。
2.2.2 页面质量
经验:
- 页面质量包含两个方面:技术上、内容上;
- 技术上,一个页面包括:url、html、http head,head很重要,
a. 首先技术上不能出错,比如返回码200,比如下面这个是英文网页,但是head中的content-language却是中文,那么网站就只会给中国人看;
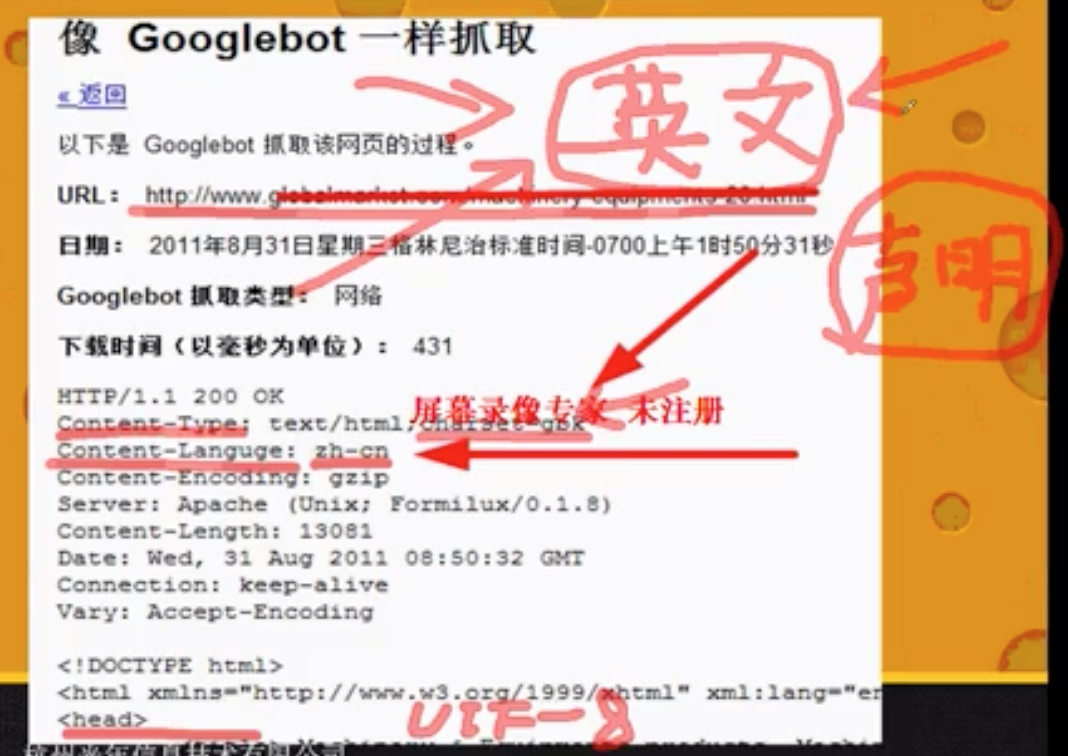
b. 其次,技术上要优化,可以参考《搜索引擎优化(SEO)新手指南》来做,比如通过在head中增加last-modify-time来减少搜索引擎重复收录工作量,留出时间去抓取更重要的页面;(可以通过http 1.1协议手册进行深入了解;)
c. 对于动态网页,默认是没有last-modify-time字段的,搜索引擎会通过content-length是否有变化来判断网页有没有变化;(百度的某个指南中有隐晦的提及) - 内容上

a. 原创内容肯定会被收录;原创内容影响网站权重,网站权重影响收录和排名。所以原创是非常非常重要的怎么强调都不为过。
b. 相对的,内容重复就是错的,内容重复不是小问题,一定要避免网站的内容重复。为了解决内容重复性识别的问题搜索引擎退出多种方案:- 网页静态化 - 唯一性参数 - nofollow - robots.txt
c. 伪原创,伪原创是不会生效的,现在生效只能说明碰巧还凑效。常见伪原创方法:替换关键词、掐头去尾等。搜索引擎比对页面是否相同的方法:先净化网页头尾,找到正文,再通过判断特征码(比如标点符号使用规律)。
d. 国平老师曾经做过三个测试站,为了提高网站权重,需要搞很多的原创内容,但是仅仅是测试,不可能花大成本去真正创作。国平老师用的方法是:找一些爬虫未爬到的地方采集内容放到测试站上。这是一种黑帽方法。2.3 网站整体排名
经验: - 首先说明,单个页面的排名和网站整体排名是两回事,操作方式也是不同的。
- 你对网站的改动一般需要3天的时间,会在google上体现出来。
- 一个页面的流量,大都是很多种关键词组合后贡献的,比如100个IP,由A-B-C几个关键词组合贡献了2个IP,由D-E两个关键词贡献了3个IP,由X-Y-Z关键词贡献了8个IP。

- 长尾词贡献精准流量,热门词因为很多网页都会命中几乎没有精准流量。
- 百度一天的搜索,90%以上的是长尾关键词,不到10%(更多行业是5%)的是热门关键词。
- 自查:你的网站是由哪些网页贡献了流量?某个网页是由哪些关键词贡献了流量?
三、总结:如何做可控的SEO?
一句话:将影响SEO的因素都数据化,确保流量的涨跌都要知道原因,知道涨的原因你可以涨更多,知道跌的原因你可以解决问题。
具体是三个方面:
- 影响因素,这个其实非常多
- 将因素数据化
- 长期观察数据间关系,积累经验
四、其他
1、服务器日志分类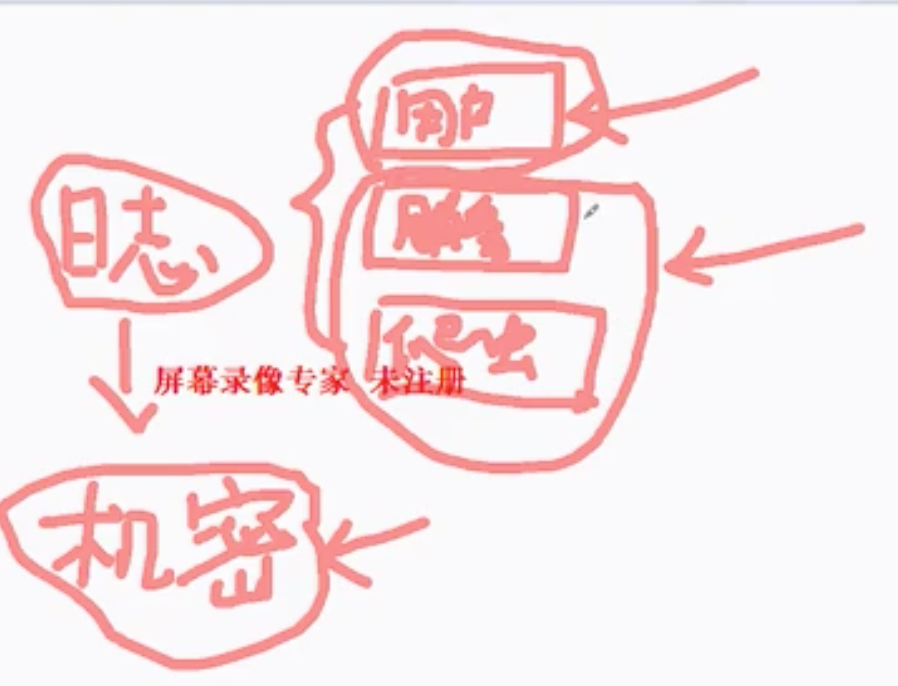
日志文件中包括:
- 用户访问记录(这部分是机密)
- 服务器日志(错误等)
- 爬虫日志
我们只需要后面两类日志即可。
五、培训视频获取
关注公众号“支离书”,回复“SEO教程”领取课程视频。